VoxPoser
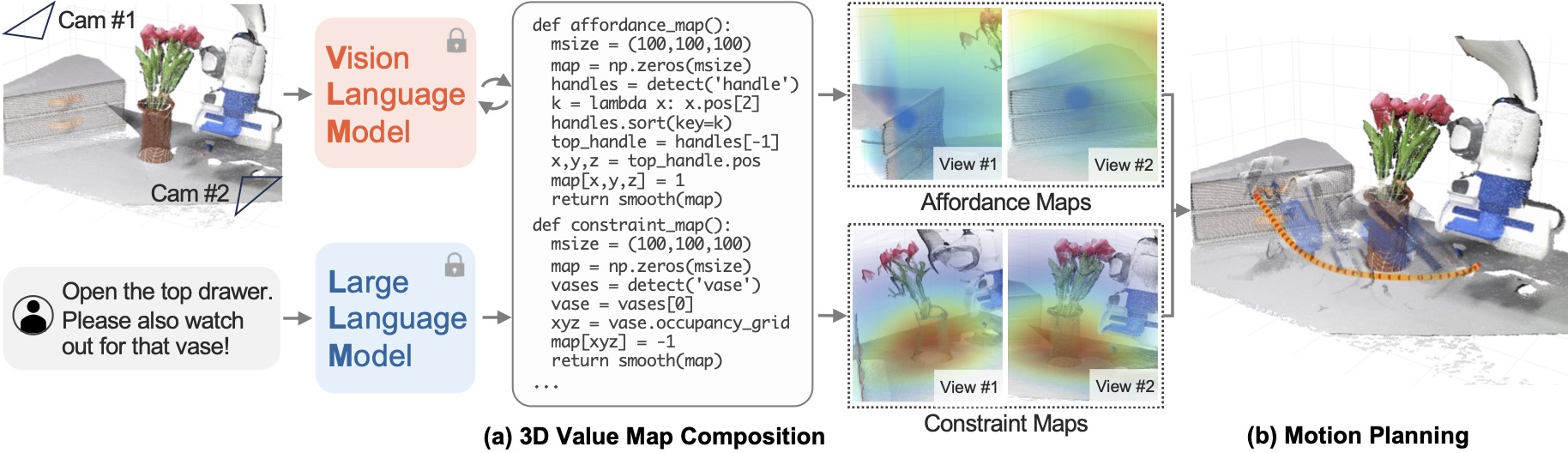
Given the RGB-D observation of the environment and a language instruction, LLMs generate code, which interacts with VLMs, to produce a sequence of 3D affordance maps and constraint maps (collectively referred to as value maps) grounded in the observation space of the robot (a). The composed value maps then serve as objective functions for motion planners to synthesize trajectories for robot manipulation (b). The entire process does not involve any additional training.
Interactive Visualization
Interactive Value Map 1
Interactive Value Map 2
Execution under Disturbances
Because the language model output stays the same throughout the task, we can cache its output and re-evaluate the generated code using closed-loop visual feedback, which enables fast replanning using MPC. This enables VoxPoser to be robust to online disturbances.
"Sort the paper trash into the blue tray."
"Close the top drawer."
Emergent Behavioral Capabilities

Prompts
Prompts in Real-World Environments:
Planner |
Composer |
Parse Query Object |
Get Affordance Maps |
Get Avoidance Maps |
Get Rotation Maps |
Get Velocity Maps |
Get Gripper Maps
Prompts in Simulation Environments (planners are not used in simulation):
Composer |
Parse Query Object |
Get Affordance Maps |
Get Avoidance Maps |
Get Rotation Maps |
Get Velocity Maps |
Get Gripper Maps
BibTeX
@article{huang2023voxposer,
title={VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models},
author={Huang, Wenlong and Wang, Chen and Zhang, Ruohan and Li, Yunzhu and Wu, Jiajun and Fei-Fei, Li},
journal={arXiv preprint arXiv:2307.05973},
year={2023}
}